
Blog by Sanjeev panday | Digital Diary
" To Present local Business identity in front of global market"
Scan QR code to visit our website
" To Present local Business identity in front of global market"
Scan QR code to visit our website
 Digital Diary Submit Post
Digital Diary Submit Post
परिभाषा (Definition):
"कंप्यूटर नेटवर्क प्रोटोकॉल नियमों और डिजिटल संकेतों का वह मानक समूह (Set of Rules) है, जो यह निर्धारित करता है कि एक नेटवर्क से जुड़े दो या दो से अधिक कंप्यूटर आपस में डेटा कैसे भेजेंगे, प्राप्त करेंगे और उसे कैसे समझेंगे।"
इसे और आसान भाषा में ऐसे समझें: जैसे सड़क पर चलने के लिए Traffic Rules होते हैं ताकि गाड़ियाँ आपस में न टकराएं, वैसे ही इंटरनेट पर डेटा सही पते पर पहुँचने के लिए Network Protocols होते हैं।
इसके मुख्य 3 काम (Core Functions):
उदाहरण (Example):
अगर आप अपने दोस्त को WhatsApp मैसेज भेजते हैं, तो पीछे TCP/IP प्रोटोकॉल काम करता है जो यह पक्का करता है कि मैसेज आपके दोस्त के ही फोन पर जाए और सही क्रम में पहुँचे।
1. सबसे महत्वपूर्ण (Foundation Protocols)
2. वेब और इंटरनेट ब्राउज़िंग (Web Protocols)
3. फाइल और ईमेल (File & Email Protocols)
4. कनेक्टिविटी और एड्रेसिंग (Connectivity Protocols)
5. सुरक्षा (Security Protocols)
1. Routing Protocols (रास्ता तय करने वाले - Deep Detail)
जब डेटा एक शहर से दूसरे शहर जाता है, तो ये प्रोटोकॉल तय करते हैं कि कौन सा 'मोड़' लेना है:
2. IP एड्रेसिंग और उसके "साथी" (Internet Layer)
3. डेटा डिलीवरी के "मैनेजर" (Transport Layer)
4. एप्लीकेशन और मैनेजमेंट (The Big List)
5. एडवांस्ड और सुरक्षा प्रोटोकॉल्स (The Missing Bits)
6. IoT और वायरलेस (Modern Protocols)
"What is Python in Hindi (पाइथन क्या है?)
Python एक बहुत ही प्रसिद्ध और शक्तिशाली प्रोग्रामिंग language है, जिसे 1980 के दशक में Guido van Rossum ने विकसित किया था। यह भाषा सरल syntax और readability के लिए जानी जाती है।
पाइथन का उपयोग web development, data science, machine learning, artificial intelligence, automation, और scientific computing जैसे कई क्षेत्रों में होता है।
यह बहुत ही अच्छी प्रोग्रामिंग लैंग्वेज है क्योंकि इसके द्वारा बहुत तेजी से एप्लीकेशन को विकसित किया जा सकता है. और यह dynamic typing तथा dynamic binding के options देता है.
बहुत सारीं बड़ी कंपनियां भी python का प्रयोग करती है जैसे:- youtube, quora, instagram, तथा google आदि.
सन् 1991 में पाइथन को launch किया गया. तथा जनवरी 1994 में पाइथन का पहला edition python 1.0 निकाला गया. इस edition में इसके नए features जैसे:- lambda, map, filter आदि आये थे. अभी पाइथन का new version 3.13 market में उपलब्ध है.
Python एक open source है. इसके लिए कोई भी पैसा नहीं लगता. तथा इसके लिए किसी भी लाइसेंस की जरुरत नहीं पड़ती. क्योंकि पाइथन GPL (general public license) के अंतर्गत उपलब्ध है. इसके नए version को पाइथन की official वेबसाइट से डाउनलोड किया जा सकता है.
पाइथन की विशेषताएं (Features of Python in Hindi)
सरल और पढ़ने योग्य (Simple and Readable): पाइथन का syntax बहुत ही सरल और क्लीन होता है, जिससे नए users के लिए इसे सीखना आसान हो जाता है। English जैसे words का इस्तेमाल होने के कारण यह language आसान लगती है।
मल्टी-पैराडाइम (Multi-Paradigm): पाइथन एक multi-paradigm language है, जिसका मतलब है कि आप object-oriented, procedural, और functional programming का इस्तेमाल कर सकते हैं।
इंटरप्रेटेड (Interpreted): पाइथन एक interpreted language है, जिसका मतलब है कि कोड को compile करने की जरूरत नहीं होती। पाइथन interpreter कोड को लाइन-बाय-लाइन execute करता है, जिससे error ढूंढना आसान हो जाता है।
प्लेटफॉर्म इंडिपेंडेंट (Platform Independent): पाइथन platform-independent है, यानी एक बार कोड लिखने के बाद, इसे किसी भी operating system जैसे Windows, Mac, या Linux पर रन किया जा सकता है।
बड़ी लाइब्रेरी सपोर्ट (Large Library Support): पाइथन में एक बहुत बड़ी library होती है, जिसमें कई predefined modules और packages होते हैं, जैसे कि NumPy, Pandas, Matplotlib, आदि।
इसे पढ़ें:-
पाइथन का उपयोग (Uses of Python in Hindi)
Python का उपयोग निम्नलिखित क्षेत्रों में किया जाता है:-
वेब डेवलपमेंट (Web Development): पाइथन का इस्तेमाल web development के लिए किया जाता है। Django और Flask जैसे frameworks का इस्तेमाल करके जटिल web applications को आसानी से बनाया जा सकता है।
डेटा साइंस और मशीन लर्निंग (Data Science and Machine Learning): पाइथन data analysis, machine learning, और artificial intelligence के लिए एक बेहतरीन language है। Pandas, NumPy, TensorFlow, और Scikit-learn जैसी libraries data handling और machine learning में इस्तेमाल होती हैं।
स्क्रिप्टिंग और ऑटोमेशन (Scripting and Automation): पाइथन scripting और automation कार्यों को आसानी से करने में मदद करता है। इसके सरल syntax और libraries की वजह से लगातार होने वाले कार्यों को आसानी से automate किया जा सकता है।
गेम डेवलपमेंट (Game Development): पाइथन game development के लिए भी इस्तेमाल हो सकता है। Pygame जैसे libraries से games बनाए जा सकते हैं।
एप्लिकेशन डेवलपमेंट (Application Development): पाइथन का उपयोग desktop applications बनाने में भी होता है। PyQt और Tkinter जैसे tools से user-friendly applications बनाए जा सकते हैं।"
Read Full Blog...
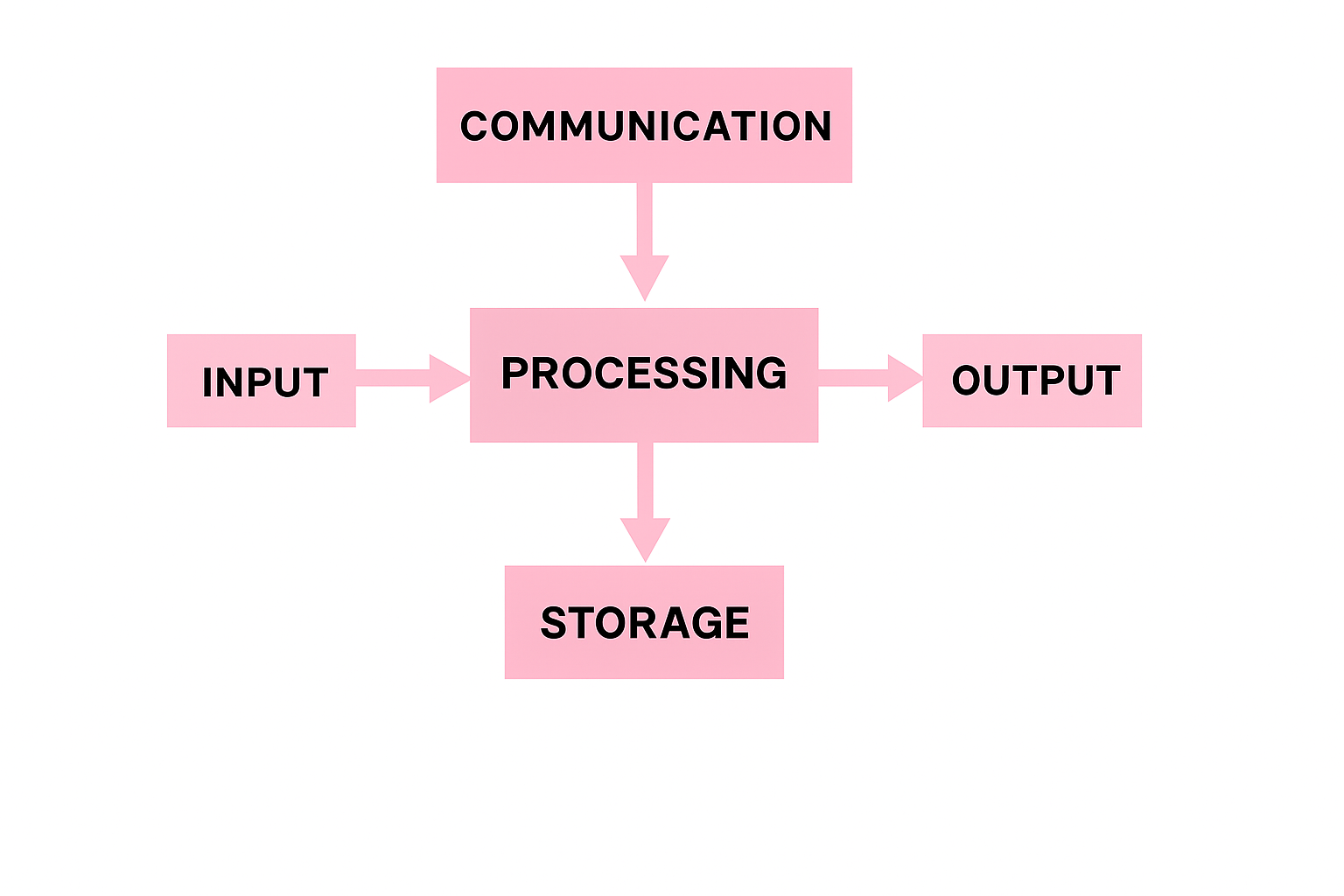
कंप्यूटर डेटा को संसाधित (process) करने के लिए कुछ निश्चित चरणों से गुजरता है। इन चरणों को कंप्यूटर प्रोसेसिंग चक्र कहा जाता है। यह मुख्य रूप से पाँच भागों में विभाजित है -
इस चरण में डेटा या निर्देश कंप्यूटर में डाले जाते हैं।
उदाहरण: की-बोर्ड, माउस, स्कैनर आदि।
इसका कार्य है कच्चा डेटा (Raw Data) को सिस्टम में भेजना।
यह कंप्यूटर का मुख्य चरण है जहाँ CPU (Central Processing Unit) डेटा को प्रोसेस करता है।
इसमें गणनाएँ, तुलना और लॉजिकल कार्य किए जाते हैं।
यह इनपुट को उपयोगी आउटपुट में बदलता है।
प्रोसेसिंग के बाद प्राप्त परिणाम को उपयोगकर्ता को दिखाया या प्रदान किया जाता है।
उदाहरण: मॉनिटर, प्रिंटर, स्पीकर आदि।
डेटा और परिणामों को भविष्य में उपयोग के लिए सहेजकर रखा जाता है।
स्टोरेज दो प्रकार की होती है:
प्राइमरी मेमोरी (Primary Memory) – अस्थायी (Temporary)
सेकेंडरी मेमोरी (Secondary Memory) – स्थायी (Permanent)
यह चरण कंप्यूटरों के बीच डेटा या जानकारी साझा करने के लिए होता है।
उदाहरण: इंटरनेट, ईमेल, नेटवर्किंग आदि।
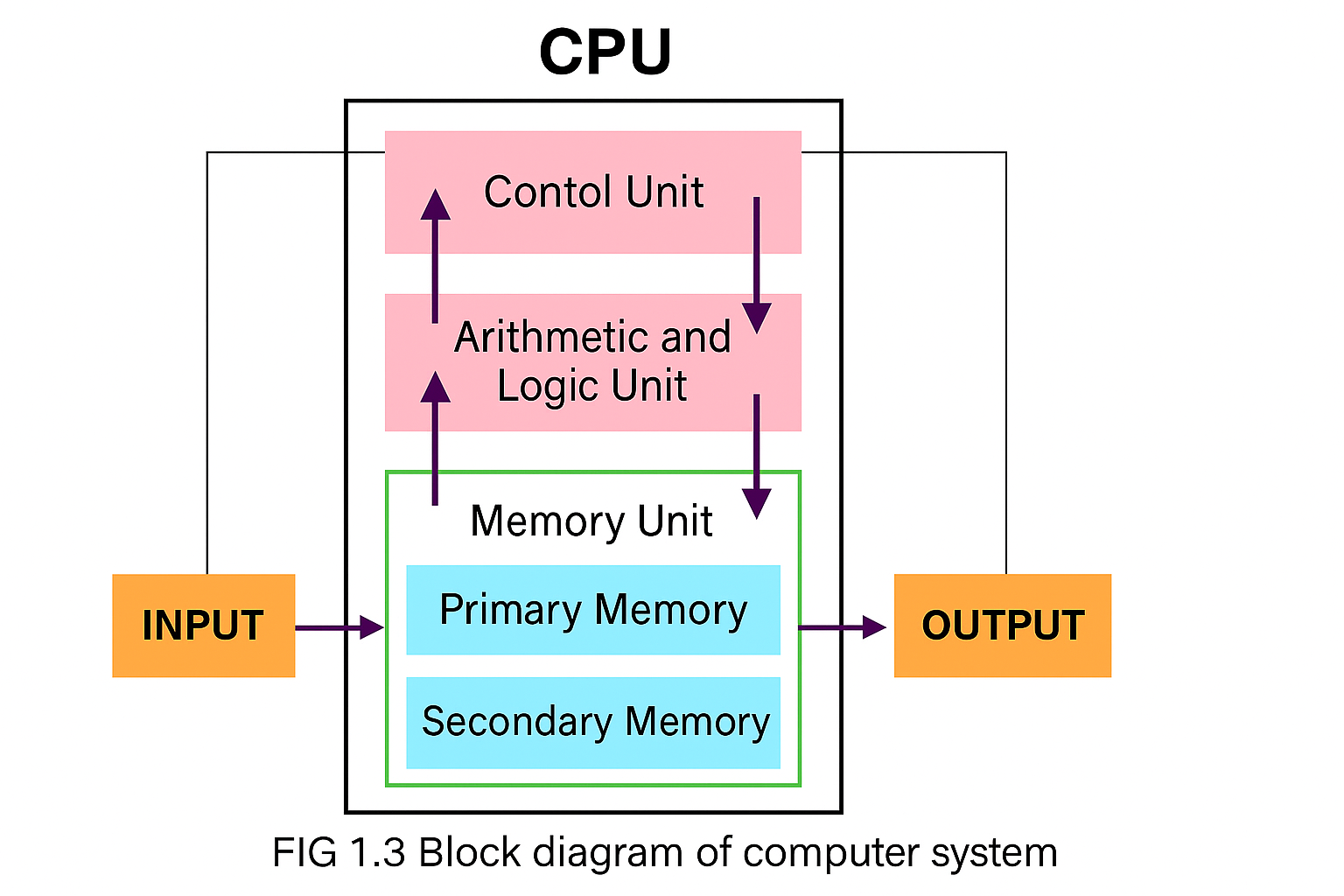
कंप्यूटर सिस्टम मुख्य रूप से चार भागों में बंटा होता है - (1) इनपुट यूनिट (Input Unit) (2) सीपीयू (CPU - Central Processing Unit) (3) मेमोरी यूनिट (Memory Unit) (4) आउटपुट यूनिट (Output Unit)
इनपुट यूनिट का कार्य डेटा और निर्देशों को कंप्यूटर में प्रवेश कराना है।
यह यूज़र और कंप्यूटर के बीच माध्यम का काम करती है।
उदाहरण: कीबोर्ड, माउस, स्कैनर, माइक्रोफोन आदि।
CPU को कंप्यूटर का मस्तिष्क (Brain) कहा जाता है। यह तीन भागों में विभाजित होता है ?
(A) कंट्रोल यूनिट (Control Unit)
यह सभी कार्यों को नियंत्रित करती है।
यह बताती है कि कौन सा कार्य कब और कैसे होगा।
यह निर्देशों को सही क्रम में निष्पादित करवाती है।
(B) अंकगणितीय और लॉजिक यूनिट (Arithmetic and Logic Unit - ALU)
यह सभी गणनाएँ (जोड़, घटाव, गुणा, भाग) और लॉजिक कार्य (तुलना आदि) करती है।
यह वास्तविक प्रोसेसिंग यूनिट होती है।
(C) मेमोरी यूनिट (Memory Unit)
यह डेटा और निर्देशों को अस्थायी या स्थायी रूप से संग्रहित करती है।
इसके दो प्रकार होते हैं:
प्राथमिक मेमोरी (Primary Memory): RAM, ROM आदि।
द्वितीयक मेमोरी (Secondary Memory): हार्ड डिस्क, पेन ड्राइव, CD आदि।
आउटपुट यूनिट का कार्य कंप्यूटर से प्राप्त परिणामों को यूज़र तक पहुँचाना है।
उदाहरण: मॉनिटर, प्रिंटर, स्पीकर आदि।
Input Unit डेटा लेती है।
CPU उस डेटा को प्रोसेस करता है (ALU और Control Unit के द्वारा)।
Memory Unit अस्थायी रूप से डेटा स्टोर करती है।
Output Unit परिणाम को बाहर प्रदर्शित करती है।
Read Full Blog...
C++ का परिचय (Introduction of C++)
C++ एक ऑब्जैक्ट ओरिएन्टिड प्रोग्रामिंग (OOP) भाषा है। यह Bjarne Stroustrup के द्वारा New Jersey, Murrary Hill में AT&T Bell Laboratories में 1979 में विकसित की गई थी। C++, C भाषा का विस्तृत रुप है। प्रारम्भ में इसका नाम "C with classes" था। 1983 में इसका नाम बदलकर C++ कर दिया गया। C++ नाम का विचार इनक्रीमेन्ट ऑपरेटर (++) के नाम से आया है। यह C भाषा का सुपर सेंट है। C++ में सबसे महत्त्वपूर्ण सुविधा जो ८ भाषा के बदले में जोडी गई है। वह क्लास, ऑब्जैक्ट, इनहैरिटैन्स, ऑपरेटर तथा फंक्शन आवरलोडिंग है। C++ के ऑब्जेक्ट ओरिएन्टिड विशेषता के कारण यह हमें प्रोग्राम को साफ, विस्तृत रुप में तथा सरल
जिस तरह से आप जब भी किसी नई भाषा को सीखना शुरू करते हैं तो सबसे पहले आप उस भाषा के अक्षरों का ज्ञान प्राप्त करते हैं। ठीक उसी प्रकार अन्य सभी भाषाओं की तरह C++ में अक्षरों (कैरेक्टरों) का एक समूह होता है जिसे इसमें प्रोग्राम बनाते समय प्रयोग में लिया जा सकता है।
अंक (Digit) : 0 से 9 तक = 0123456789
ABCDEFGHIJKLMNOPQRSTUVW
XYZ
C++ में टोकन प्रोग्राम का वह छोटे से छोटा भाग होता है जो कम्पाइलर के लिए मान्य होता है और उसका अपना एक मतलब होता है। C++ में सामन्तय निम्न प्रकार के टोकन्स होते है
अभिव्यक्ति को व्यक्त करने हेतु, संदेश प्रेषित अथवा संवाद स्थापित करने हेतु किसी माध्यम की आवश्यकता होती है। इस प्रकार के किसी माध्यम को हम भाषा कहते हैं। भाषाएँ कई प्रकार की होती हैं तथा यह भौगोलिक परिस्थितियों के अनुरुप बदलती रहती हैं।
कम्प्यूटर के अविष्कार के साथ कम्प्यूटर से सम्बन्ध स्थापित करने हेतु भाषा का अविष्कार किया गया। आवश्यकता के अनुरुप स्नैः-स्नैः भाषा समृद्ध होती गयी तथा मशीन लैंग्वेज से असेम्बली लैंग्वेज होते हुए आज कम्प्युटर के साथ सम्बन्ध स्थापित करने हेतु हम किसी साधारण भाषा से मिलती-जुलती हाई लेवेल लैंग्वेज का उपयोग करते हैं।
वाक्यों को गढ़ने की विधि को हम सिन्टैक्स (Syntax) तथा उनकी अभिव्यक्ति को सिमान्टिक्स (Symantics) कहते हैं। अक्षरों के समूह को शब्द तथा शब्दों के समूह को, जिनका कुछ अर्थ हो, वाक्य कहा जाता है। शब्द दो प्रकार के होते है-सार्थक तथा निरर्थक।
सभी प्रोग्रामिंग भाषाओं को दो वर्गों में विभाजित किया गया है. हाई– लेवल लैंग्वेजेस (High-Level Languages) और लो-लेवल लैंग्वेजेस (Low-Level Languages) |
"बेसिक कम्बाईन्ड प्रोग्रामिंग लैंग्वेज' (बीसीपीएल) ["Basic Combined Programming Language' (BCPL)] कैम्ब्रिज यूनिवार्सिटी में माट्रिन रिचार्डस द्वारा विकसित किया गया था। उसी समय ए टी एण्ड टी के बेल लेब के केन थॉम्पसन द्वारा बी (B) नामक भाषा को विकसित किया जा रहा था। डेन्नीस रिच्ची ने बी और बीसीपीएल की विशेषताओं का उपयोग करते हुए उसमें निज के द्वारा विकसित कोड जोड दिया और सी भाषा का विकास किया। इसलिए सी को बी भाषा का उत्तराधिकारी भी कहा जाता है। युनिक्स ऑपरेटिंग सिस्टम के साथ यह विकसित हुआ। सी एम एस डॉस ऑपरेटिंग सिस्टम पर भी उपलब्ध है।
सी में हाई–लेवल लैंग्वेज की विशेषताओं के साथ-साथ असेम्बली लैंग्वेजेस की क्षमता का भो मिश्रण है। अतः यह दोनों प्रकार के सॉफ्टवेयर यथा सिस्टम सॉफ्टवेयर तथा एप्लीकेशन पैकेजेस को लिखने के लिए उपयुक्त है।
सी में लिखे गये प्रोग्राम अधिक सार्थक तथा तीव्र गति से कियान्वित किये जाने योग्य होते हैं। यह सम्भव हो सका है सी में उपलब्ध डाटा टाइप की समृद्ध ऋखला तथा प्रभावी ऑपरेटरों के कारण यह बेसिक से कई गुना तेज है उदाहरण के लिए. 0 से 15000 तक के वेरियबल्स को सृजित करने हेतु सी में लगभग 1 सेकेन्ड लगता है जबकि बेसिक में 50 सेकेन्डस से अधिक लगता है।
सी अधिक सुवाह्य है। इसका अर्थ यह है कि एक कम्प्यूटर के लिए लिखा गया सी प्रोग्राम को बिना संशोधन अथवा नाममात्र के संशोधनों के पश्चात दूसरे कम्प्यूटर पर चला सकते हैं।
सी की दूसरी मुख्य विशेषता है अपने आप विस्तार करने की क्षमता। सी प्रोग्राम मूल रूप में फंक्शनों का संग्रह है जो सी लायब्रेरी में उपलब्ध होती है। हम अपने फक्शनों को सी लायब्रेरी में जोड़ सकते हैं।
सी प्रोग्रामिंग स्ट्रक्चर (C programming structure)
सी प्रोग्राम में अनिवार्य रूप से निम्नलिखित भाग होते हैं
1. हेडर स्ट्रक्चर (Header structure)
2. फंक्शन Main() [Function Main())
3. प्रोग्राम की शुरूआत (Start of program)
4. वैरियबल डिक्लेरेशन तथा मूल्यों को निर्धारित/आंवटित करना (Variable declaration and assigning values)
5. प्रोग्राम स्टेटमेंट्स अथवा प्रोग्राम बॉडी (Program Statements)
6. प्रोग्राम का अंत (End of program)
सरल सी प्रोग्राम को लिखना (Writing simple C program)
निम्नलिखित उदाहरण सी प्रोग्राम के स्ट्रक्चर को प्रदर्शित करता है।
#include <stdio.h> (1)
#include <conio.h> (2)
/* A sample C program */ (3)
void main() (4)
{ (5)
int a, b, c; (6)
a=2; (7)
b = 3; (8)
c= a*b + (a+b); (9)
printf ("c= %d', c); (10)
getch(); (11)
} (12)
उपरोक्त सरल सी प्रोग्राम स्ट्रक्चर की व्याख्या
लाइन सं० व्याख्या
1,2 हेडर फाइले
3 कमेंट लाईन। 4 मुख्य कंक्शन का नाम तथा उसका प्रकार। फक्शन नाम के साथ छोटे कोष्ठकों का उपयोग किया जाता है। जिसके माध्यम से आरग्यूमेंट्स प्रेषित किया जाता है।
5 खुला कोष्ठक प्रोग्राम के प्रारंभ को सूचित करता है।
6 इटीजर टाईप (प्रकार) के वेरियबल को परिभाषित किया गया है।
7,8,9 वेस्थिबल को निर्धारित किया गया है।
10 printi स्टेटमेंट का उपयोग करके परिकलित मूल्यों को प्रिन्ट किया गया है।
11 एक फंक्शन है।
12 बंद कोष्ठक प्रोग्राम के अंत को सूचित करता है।
शब्दों संख्याओं और अभिव्यक्त्तियों को दर्शाने हेतु उपयोग किये जाने वाले वर्ग, लिपि अधवा प्रतीक (कैरेक्टर) कम्प्यूटर विशेष पर निर्भर करते है फिर भी कुछ करेक्टर ऐसे हैं जो प्राय सभी प्रकार के कम्प्यूटरो, जैसे कि, पर्सनल माईकर, मिनी तथा मेनफेम कम्प्यूटरों में उपयोग किये जा सकते हैं। सी मे कैरेक्टरों को निम्नलिखित वगों में वर्गीकृत किया गया है:
1. वर्ण (ALPHABETS)
2 अंक (DIGITS)
3. विशेष प्रतीक (SPECIAL CHARACTERS)
4. डाईट स्पेसेस (WHITE SPACES)
निम्न कैरेक्टर के सेट को सी में उपयोग किया जाता है।
वर्ण : A to Z, a to z.
अंक : 0 to 9
विशेष प्रतीक
अथवा स्पेशल कैरेक्टर : * + \ " ( = | { # } ~ ; } / % - [ , ? ^ _ ] ' . & blank
हाईट स्पेसेस Blank space, Horizontal Tab, Carriage return, New line, Form feed.
सी में कॉन्स्टेन्ट्स नियत मूल्यों को प्रदर्शित करता है जो प्रोग्राम के निष्पादन पर्यन्त बदलता नहीं है। संख्याओं को न्यूमेरिक कॉन्स्टेन्ट्स कहते है। न्यूमेरिक कॉन्स्टेन्टस के उदाहरण 1,12,24,67-74 है। न्यूमेरिक कॉन्स्टेन्ट्स दो प्रकार के है:
(i) इंटीजर कॉन्स्टेन्ट्स (Integer Constants)
(ii) रिवल कॉन्स्टेन्ट्स (Real Constants)
ये पूर्ण संख्यायें होती है। इंटीजर कान्सटेन्ट्स में आप दशमलव का प्रयोग नहीं कर सकते हैं। ऐसी सख्याएं धनात्मक अथवा ऋणात्मक (Positive or Negative) हो सकती है। 56, 78,-34, 98 तथा 0 कॉन्सटेन्ट्स के उदाहरण है। इंटीजर कॉन्स्टेन्ट्स की रेन्ज (प्रसार) -128 से +127 तक अथवा -256 से +255 अथवा 512 से +511 हो सकती है। निम्नलिखित नियम एक इंटीजर कॉन्स्टेन्टस की रेन्ज दर्शाता है। यदि एक कम्प्यूटर n बिट वर्ड का है तो वैध / स्वीकृत इंटीजर का परिणाम -2n-1 और 2n-1 के मध्य होगा। एक इंटीजर कॉन्स्टेन्ट कम से कम एक अंक का हो सकता है। इसमें दशमलव का उपयोग नहीं होना चाहिए। यह धनात्मक अथवा ऋणात्मक हो सकता है। . यदि किसी चिह्न का उपयोग नहीं किया गया हो तो इंटीजर कॉनटेन्ट घनात्मक होता है। संख्या के अन्तर्गत खाली स्थान या विशेष प्रतीको अथवा चिन्हों कैरेक्टरों को इंटीजर कॉन्स्टेन्ट में अनुमति नहीं है। इटीजर कॉन्सटेन्ट में किती प्रकार के अन्य कैरेक्टर अथवा खाली जगह / रिक्त स्थान (Space) का उपयोग वर्जित है। इंटीजर कॉन्स्टेन्ट्स हेतु स्वीकृत परिणाम -32768 to +32767 है। उदाहरण के लिए 08 अमान्य डेसिमल इंटीजर है। इसे सिफ 8 ही लिखना चाहिए। यदि प्रथम अंक शून्य (0) हो तो. उसे ऑक्टल नंबर के रूप में समझा जाता है। इसी तरह सी भाषा हेक्साडेसिमल संख्याओं को दर्शाता है। हेक्ताडेसिमल संख्या OX या Ox के साथ शुरू होती हैं।
कुछ मान्य और अमान्य इंटीजर कॉन्स्टेन्ट्स को नीचे दर्शाया गया है।
38
0
-127
+789
_________________________________________
कॉन्स्टेन्ट अमान्यता का कारण
_________________________________________
67.99 दशमलव की अनुमति नहीं है।
6,934 कॉमा की अनुमति नहीं है।
45*4 विशेष कैरेक्टरों की अनुमति नहीं है।
432+ संख्या (नंबर) के बाद + चिन्ह का उपयोग
नहीं किया जाना चाहिए।
_________________________________________
सी में चार प्रकार के इंटीजर कॉन्स्टेन्ट्स हैं. वे लॉंग इंटीजर, शॉर्ट इंटीजर, इंटीजर और अनसाईन्ड इंटीजर हैं। ऊपर दिये गये इंटीजर कॉन्स्टेन्ट्स के समस्त नियम अन्य तीनों प्रकारों इंटीजर के लिए भी लागू होता है। शॉर्ट इंटीजर को लॉंग इंटीजर की तरह समझा जाता है।
यदि अधिक परिमाण वाले मूल्यों को प्रदर्शित करना/दर्शाना है. तो लॉंग इंटीजर का उपयोग किया जाता है। यह घनात्मक अथवा ऋणात्मक इंटीजर हो सकता है। यदि कम्प्यूटर का वर्ड लेंथ n है. लॉग इंटीजर के -2n-1 से 2n-1 के मध्य रहेगा। लॉग इंटीजर कॉन्स्टेन्ट्स वर्ण L के साथ समाप्त होता है (अपर केस या लोवर केस)। कुछ मान्य लॉग इंटीजर हैं-5764845L, 879576L और 54835658L.
शार्टइंटीजर छोटे परिमाण वाली संख्याओं को दर्शाने के लिए उपयोग किया जाता है। शार्टइंटीजर को लोंग इंटीजर के रूप में भी परिवर्तित किया जा सकता है। लेकिन शार्टइंटीजर के रूप में घोषणा प्रक्रिया की तेज़ी का सुधार करता है। यदि कम्प्यूटर का वर्ड लेन्थ n है, शॉट इंटीजर की वैल्यू -2n/2-1 से 2n/2-1 -1के मध्य होगा।
इंटीजर मध्यम आकार की संख्याओं को दर्शाता है। यदि कम्प्यूटर का वर्ड लॅन्थ n है. तो इंटीजरों की रेन्ज -2n/2-1से 2n/2-1 -1 होती है।ऋणात्मक संख्याओं को भी दर्शाने के कारण इंटीजर को साईन्ड इंटीजर भी कहा जा सकता है। ऋण चिन्ह (-) की अनुपस्थिति का अर्थ है संख्या धनात्मक इंटीजर है।
_________________________________________
इंटीजर प्रकार (Integer type) दर (Range)
_________________________________________
Short limeger 2n/2-1 to 2n/2-1-1.
Integer 2n-1 to 2n-1-1
Unsigned Integer 0 to 2n-1
Long Interger 2²n-1 to 2-1-1
__________________________________________
इस प्रकार के इंटीजरों को घनात्मक इंटीजरों के लिए उपयोग किया जाता है. यदि कम्प्यूटर की वर्ड लेंन्ध n हो तो, अनसाईन्छ इंटीजर 0 से 2n-1 -1तक के मूल्यों को रख सकता है। अनसाईन्ड इंटीजर कॉन्स्टेन्ट्स को u के साथ उचित स्थिति पर लिखा जाता है (अप्पर केस या लोवर केस)। अनसाईन्ड इंटीजर के उदाहरण 654uऔर 287 U है।
कभी कभी इंटीजर संख्याएँ मात्राओं को प्रस्तुत करने के लिए अपर्याप्त होते हैं क्योंकि दूरी, ऊँचाई, तापमान, मूल्य इत्यादि में है। ऐसी संख्याओं को रियल या फ्लोटिंग पोईन्ट कॉन्स्टेन्ट्स कहा जाता है। 67.34, 4.8923 और 453.0 कुछ रियल कॉन्स्टेन्ट्स के उदाहरण हैं।
निम्नलिखित दो रूपों में से किसी एक में एक रियल कॉन्स्टन्ट को प्रकट किया जा सकता है।
i) फ्राक्शनल फॉर्म (Fractional form)
ii) एक्सपोनेंशियल फॉर्म (Exponential form)
प्राक्शनल फॉर्म में रियल कॉन्स्टन्ट के लिए निम्नलिखित नियम लागू हाता है।
o एक रियल कॉन्स्टन्ट में कम से कम एक डिजिट होना चाहिए।
o एक डेसिमल पाईन्ट अथवा दशमलव होनी चाहिए।
o यह संख्या घनात्मक अथवा ऋणात्मक हो सकती है।
o डिफाल्ट चिन्ह घनात्मक है अथवा कोई भी चिन्ह न हो, तो संख्या को धनात्मक समझना चाहिए।
o खाली स्थान तथा * जैसे विशेष प्रतीकों रियल कॉन्स्टेन्ट में स्दीकाई और मान्य नहीं है।
(i) फ्लोटिंग पॉइन्ट (Floating point)
(ii) डबल (Double
एक जोडे उद्धरण चिन्हों के अंदर संलग्न किसी एक अक्षर को कैरेक्टर कहा जाता है। कम्यूटर में उपयोग किये जाने वाले कैरेक्टर सेंट के आधार पर प्रत्येक कैरेक्टर का एक इंटीजर वैल्यू / मूल्य होता है। साधारणतया ASCII कैरेक्टर सेट का उपयोग होता है। इस कैरेक्टर सेट के अनुसार कुछ कैरेक्टर कॉन्स्टेन्ट्स और उनके इटीजर वैल्यू को नीचे दर्शाया गया है।
____________________________________
कॉन्स्टेन्ट (Constant) मूल्य (Value)
____________________________________
A 65
A 97
Z 90
Z 122
# 35
& 38
_____________________________
_____________________________
कॉन्स्टेन्ट्स अमान्यता का कारण
_____________________________
'A मात्र एक उद्धरण चिन्ह का उपयोग किया गया है। ('A' मान्य है।)
"a' डबल उद्धरण चिन्ह की अनुमति नहीं है।
"INDIA' मात्र एक कैरेक्टर की अनुमति है।
स्ट्रिंग कॉन्स्टेन्ट डबल उद्धरण चिन्ह (" ") से घिरे कैरेक्टरों की पंक्ति ( अनुक्क्रम) है। स्ट्रिंग कॉन्स्टन्ट के कैरेक्टर अक्षर, संख्या, विशेष कैरेक्टर और खाली स्पेस हो सकते हैं।
उदाहरण
"Raju"
"Best of luck"
"3/195, Vijayant Khand"
"C"
वैरियेबल एक प्रतीकात्मक नाम है, एक प्रस्तुतिकरण representation) है। इसके कई रूप अथवा प्रकार हो सकते हैं। जैसा कि इसके अर्थ से ज्ञात होता है. इसकी कोई नियत मूल्य अथवा वैल्यू नहीं होती। इसकी वैल्यू प्रीग्राम के क्रियान्वयन के दौरान बदल सकती है।
प्रायः समस्त भाषाए एक जैसे (सामान्य प्रकार के) वैरियेबल का उपयोग करती हैं। जैसे, इंटीजर, पलोटिंग पॉइन्ट कैरेक्टर तथा स्ट्रिंग। वैरियेबल नामों में मात्र अक्षर, अंक तथा अण्डर स्कोर का उपयोग किया जा सकता है। वैरियेबल नामों की लम्बाई (लेन्थ) ऑपरेटिंग सिस्टम पर आधारित होते हैं। वैरियंबल नामों के सृजन हेतु कुछ नियम बनाये गये हैं. जो नीचे दिये गये हैं।
o वैरियेबल नाम कैरेक्टर डिजिट और अंडरस्कोर(_) का कोई मिश्रण है।
o अंडरस्कोर के अतिरिक्त कौमा खाली स्थान अथवा जगह या विशेष कैरेक्टर को नाम में नहीं जोड़ा जा सकता है।
o वैस्येिबल नाम किसी वर्ण (कैरेक्टर) अथवा (_) से प्रारम्भ हो सकते हैं।
o सी क्रियाएँ, जिनका सी में विशेष अर्थ होता है, वैरियेबल नाम के रूप में उपयोग किया नहीं की जा सकती। अर्थात सी के रिजर्व वर्ड का उपयोग वैरियेबल नाम के रूप में नहीं किया जा सकता।
o एक मान्य वैरियेबल नाम को आईडेन्टिफायर भी कहा जाता है।
उदाहरण
कुछ मान्य वैरियेबल नाम नीचे दिये गये हैं।
P
f_name
average_number
______________________________________
नाम अमान्यता के कारण
______________________________________
7a पहला अक्षर वर्ण नहीं है।
Char सी में कीवर्ड (रिजर्ल्ड वर्ड) है, जिसका विशेष अर्थ है।
1*b*h विशेष कैरेक्टर की अनुमति नहीं है।
first pgm खाली स्थान की अनुमति नहीं है।
________________________________________
वैरियेबल के विभिन्न प्रकार हैं।
1. इंटीजर वैरियेबल्स
i) लॉग इंटीजर
ii) शॉर्ट इंटीजर
iii) अनसाईन्ड इंटीजर
iv) इंटीजर
2. रियल वैरियेबल्स
i) फ्लोटिंग पॉइन्ट
ii) डबल
3. कैरेक्टर वैरियंचल
i) साईन्ड कैरेक्टर
ii)अनसाईन्क कैरेक्टर
4 स्टिंग वैरिग्रेबल
वैरियेबल का नामकरण इस प्रकार किया जाना चाहिए कि अन्य उपयोग कर्ता अथवा प्रोग्रामर भी उसे पढ़कर उसका तात्पर्य समक्ष सके। वैरियेबल्स के नामकरण में छोटे तथा बड़े अक्षर (small and capital letters) का उपयोग किया जा सकता है। परन्तु वे भिन्न होते है। उदाहरण स्वरूप And तथा and दो अलग अलग वैरियेबल माने जायेंगे। किसी वैरियेबल नाम की लम्बाई कुछ भी हो सकती है. परन्तु आपरेटिंग सिस्टम नियमानुसार उसका निर्धारण स्वयं कर लेता है।
वैरियेबल नामों को निर्धारित करने के पश्चात उन्हें परिभाषित (declare) किया जाता हैं। डिक्लरेशन दो कार्य करता है, वे हैं
1. यह प्रोग्रामर को वैरियेबल का नाम दर्शीता है।
2 वैरियेबल रखनेवाले डाटा के प्रकार (Data type) को भी दर्शाता है।
int <list of variables>;
उदाहरण के लिए टोटल, वाल्यूम तथा iइंटीजर वैरियेबल्स के रूप में दर्शाय गये हैं।
int i, total, volume;
इंटीजर वैरियेबल्स को अलग अलग पंक्ति अथवा लाईन में भी दर्शाया जा सकता है।
संख्या के आकार के अनुरूप हम इसे शार्ट अथवा लॉग इंटीजर के रूप में निम्नप्रकार से परिभाषित कर सकते हैं:
उदाहरण
नीचे दिये गये सभी मान्य डिक्लैरेशन है।
short int i, total, volume;
short i, total, volume;
Long int i, total, volume;
long i, total, volume;
unsigned int i, sum, area;
unsigned i, sum, area;
एक रिजर्ल्ड वर्ड फ्लोट को रियल वैरियेबल को परिभाषित करने के लिए उपयोग किया जाता है।
सिन्टैक्स (Syntax)
float list-of-variables;
float side, perimeter;
अधिक यथार्थता अथवा accuracy स्पष्टता के साथ वैरियेबल के वैल्यू को दर्शाने के लिए डबल अथवा फ्लोट अथवा लॉग फ्लोट का उपयोग किया जाता है।
double side, perimeter;
long float side, perimeter;
कैरेक्टर वैरियेबल द्वारा मेमोरी में मात्र 1 बाइट (8 बिट्स) का उपयोग किया जाता है। एक कैरेक्टर की इंटीजर वैल्यू -128 से 127 तक होती है। इन इंटीजर वैल्यू की सहायता से हम ASCII कैरेक्टर के रूप में मैमोरी में स्टोर करते हैं। आपको ज्ञात होगा कि ASCII कैरेक्टर सेट 'a', 'b', '$', '3' इत्यादि से बना है।
सिन्टैक्स (Syntax)
char <list-of-variables>;
char x, y;
char filmi;
अन्य डाटा टाइप की तरह स्ट्रिंग भी सी लैंग्वेज का एक डाटा टाइप है। स्ट्रिंग कान्सटेन्ट्स के बारे में हम पहले जान चुके हैं। अब हम स्ट्रिंग वैरियेबल के बारे में जानेंगे। स्ट्रिंग वैरियेबल को एक कैरेक्टर (array) के रूप में परिभाषित किया जा सकता है।
सिन्टैक्स (Syntax)
char string_name (size);
उपरोक्त उदाहरण में एक स्ट्रिंग वैरियेबल "स्ट्रिंग नेम" को परिभाषित किया गया है। वैरियेबल होने के कारण "स्ट्रिंग नेम" की लम्बाई अनिश्फित है। उक्त "स्ट्रिंग नेम" वैरियेबल की लेन्थ को साइज नाम दिया गया है। साइज लेन्ध के स्ट्रिंग वैरियेबल "स्ट्रिंग नेम" को अरे कहा जाता है।
कोई भी स्टिंग वैल्यू निर्धारित की जा सकती है। नीचे दिये गये उदाहरण में स्ट्रिंग वैरिवल कन्ट्री की वैल्यू "INDIA" निर्धारित की गयी है।
char country ( = "INDIA"
मैमोरी में कन्ट्री नाम के स्ट्रिंग वैरियवल निम्न प्रकार से संग्रहित कर सकते है।
country (0) -.'I'
country [1] = 'N'
country [2] = 'D'
country [3] = 'I'
country [4] = 'A'
1. किसी संख्या को प्राप्त करना या पढ़ना।
2. किसी संख्या को देना (या छापना)।
3. अंकगणितीय क्रियाएँ (जोड़, घटाव, गुणा तथा भाग) करन
4. दो संख्याओं की तुलना करना।
कोई प्रोग्राम कुछ निर्देशों (Instruction) का निश्चित और क्रमबद्ध समूह होता है। वे निर्देश इस प्रकार दिये (या लिखे) जाते हैं कि यदि उनका उसी क्रम में सही-सही पालन किया जाए, तो कोई कार्य पूरा हो जाए। उदाहरण के लिए, यदि आप किसी बच्चे को बाजार से कोई किताब लाने के लिए भेजते हैं, तो उसे निम्नलिखित आदेश दिय जायेंगे-
1. बाजार जाओ।
2. किताबों की दुकान पर जाओ।
3. किताब का नाम बताकर उसके बारे में पूछो।
4. यदि किताब उपलब्ध है तो उसे खरीद लो।
5. घर वापस आओ।
अब कोई भी बच्चा या व्यक्ति जो इन आदेशों को समझ सकता है और ये क्रियाएँ (आना, जाना, पूछना, खरीदना। आदि) कर सकता है, इन आदेशों के आधार पर आपकी इच्छित किताब लाकर दे सकता है। इस प्रकार ये आदेश वास्तव में एक प्रोग्राम ही हैं। इन आदेशों का इसी क्रम में पालन होना आवश्यक है। उदाहरण के लिए 'किताब के बारे मे पछना
कंप्यूटर के लिए भी हम इसी प्रकार आदेश देते हैं। इन आदेशों के समूह को ही प्रोग्राम कहा जाता है। लेकिन कंप्यूटर बाजार जाना और खरीदना जैसी क्रियाएँ नहीं कर सकता, बल्कि केवल पहले बतायी गयी पाँच प्रकार की क्रिया ही कर सकता है। इसलिए उसके लिए सभी आदेश इन क्रियाओं को करने के बारे में ही होने चाहिए। उदाहरण लिए, मान लीजिए कि आप किसी कक्षा के विद्यार्थियों की औसत उम्र निकालना चाहते हैं, तो इसके लिए आदेश इस प्रकार दिये जायेंगे-
1. कक्षा में छात्रों की संख्या को पढ़ो।
2. सभी छात्रों की उम्रों को पढ़ो।
3. उन सभी उम्रों का योग ज्ञात करो।
4. उम्रों के योग में छात्रों की संख्या से भाग देकर औसत उम्र निकालो।
5. औसत उम्र को छाप दो।
ये आदेश हमने साधारण बोलचाल की भाषा में लिखे हैं। कम्प्यूटर के लिए ये ही आदेश किसी विशेष भाषा में संक्षेप में लिखे जाते हैं। ध्यान दीजिए कि इनमें से प्रत्येक आदेश कम्प्यूटर की किसी मूल क्रिया (पढ़ना, जोड़ना, भाग देना, छापना आदि) से सम्बन्धित है। प्रत्येक कार्य करने के लिए क्रियाएँ अलग-अलग की जाती हैं
किसी कम्प्यूटर के लिए प्रोग्राम लिखने की क्रिया को प्रोग्रामिंग कहा जाता है। कम्प्यूटर को कम से कम आदेश देकर उससे अधिक से अधिक कार्य सही-सही करा लेना बहुत उपयोगी कला है। इसके लिए बहुत कौशल और ज्ञान की आवश्यकता होती है। कम्प्यूटर तो केवल एक जड़ मशौन है। उसके द्वारा बड़े-बड़े कार्य करा लेना प्रोग्रामिंग की कला का ही चमत्कार है।
जो व्यक्ति कम्प्यूटर के लिए प्रोग्राम लिखते हैं या तैयार करते हैं, उन्हें प्रोग्रामर (Programmer) कहा जाता है। कम्प्यूटर के लिए प्रोग्राम लिखने की कुछ विशेष भाषाएँ होती हैं। उन्हें प्रोग्रामिंग भाषा (Programming Languages) कहा जाता है। सी (C) ऐसी ही एक भाषा है, जिसका विस्तृत अध्ययन आप अगले अध्याय में करेंगे।
किसी भी कार्य के लिए प्रोग्राम लिखने से पहले उसकी पूरी जिना बनानी पड़ती है। समस्या को सुनते ही प्रोग्राम लिखने लग जाना गलत है। यह गलती प्रायः नये प्रोग्रामर किया आहे. परिणामस्वरूप उनका कई गुना अधिक समय उस प्रोग्राम की गलतियाँ ढूँढ़ने और उन्हें ठीक करने में लग आया है। इसके विपरीत सफल प्रोग्रामर वे होते हैं जो प्रोग्राम को योजना बनाकर चरणबद्ध तरीके से लिखते हैं और वे बहुत कम समय में सफल प्रोग्राम तैयार कर लेते हैं। इसी कारण कम्प्यूटर प्रोग्रामिंग के क्षेत्र में एक कहावत बहुत प्रोग्राम लिखना आप जितनी जल्दी प्रारम्भ करेंगे, वह उतनी ही देर में समाप्त होगा।
जब तक किसी समस्या को पूरी तरह समझ न लिया जाए, उसको हल करना या उसको कोशिश करना सम्भव नहीं है। यह एक तथ्य है कि प्रोग्राम लिखने के लिए प्रायः जो समस्याएँ दी जाती है, वे कभी भी पूर्ण नहीं होती. का न कोई बात उनमें छूट ही जाती है। अनुभवी प्रोग्रामर उस बात को शीघ्र पकड़ लेते हैं इसलिए या तो अतिरिक्त सूचनाएँ माँग लेते हैं या उसके स्थान पर अपने ज्ञान के अनुसार कल्पना कर लेते हैं। इसलिए समस्या को ठीक-ठीक समझ लेना अनिवार्य है।
आप पढ़ चुके हैं कि प्रोग्राम इनपुट डाटा पर क्रिया करने के लिए लिखे जाते हैं, इसलिए जब तक आपको यह ज्ञात न हो कि इनपुट किस रूप में होगा और किस प्रकार प्राप्त होगा, तब तक आप प्रोग्राम नहीं लिख सकते। इसलिए यह देख लेना अति आवश्यक है कि समस्या को हल करने के लिए समस्त आवश्यक इनपुट उपलब्ध है या नहीं और वह किस रूप में हैं। नये प्रोग्रामर इस तथ्य की उपेक्षा कर देते हैं, इसलिए प्रोग्राम लिखते समय भ्रम में पड़ जाते हैं।
अगले चरण में हमें आउटपुट की योजना बनानी होती है। इस चरण में ही यह स्पष्ट होता है कि हमारा प्रोग्राम वास्तव में क्या करना चाहता है। आउटपुट की योजना तैयार करते समय यह भी सुनिश्चित हो जाता है कि हमने समस्या को ठीक तरह समझ लिया है और यह भी कि हमें जो इनपुट दिया गया है, वह माँगे गये आउटपुट के लिए पर्याप्त है, अर्थात् कोई चीज छूटी नहीं है।
यह प्रोग्राम लिखने और बनाने का सबसे महत्त्वपूर्ण चरण है। इसमें हम समस्या के हल की चरणबद्ध रूपरेखा बनाते हैं। दिये हुए इनपुट से माँगे गये आउटपुट तक पहुँचने में जिन चरणों से गुजरना होता है, वं सभी चरण क्रमानुमार लिखे जाते हैं। इस क्रमबद्ध लेखन को एल्गोरिथ्म कहा जाता है। एल्गोरिथ्म वास्तव में साधारण भाषा में लिखा गया प्रोग्राम ही है। आवश्कता होने पर प्रोग्राम के उदद्देश्य को कई भागों में बाँट लिया जाता है और प्रत्येक भाग पर ध्यान केन्द्रित करके उसके लिए अलग-अलग एल्गोरिथ्म तैयार किये जाते हैं और अंत में सबको एक में मिला दिया जाता है। इस प्रकार पूरा एल्गोरिथ्म तैयार कर लिया जाता है।
एल्गोरिथ्म तैयार करने के बारे में आप अगले अनुच्छेद में विस्तार से पढ़ेंगे।
फ्लोचार्ट एल्गोरिथ्म तैयार करने और दिखाने की ही एक विधि है। इसमें किसी एल्गोरिथ्म के सभी चरणों को विशेष प्रकार की आकृतियों द्वारा दिखाया जाता है और उन आकृतियों के भीतर आवश्यक सूचनाएँ लिखी जाती हैं।
परलोचार्ट तैयार करने के बारे में आप इसी अध्याय में आगे विस्तार से पढ़ेंगे
इस चरण में ऊपर बताये गये एल्गोरिथ्म या फ्लोचार्ट के अनुसार किसी प्रोग्रामिंग भाषा में प्रोग्राम लिखा जाता है। यदि ऊपर के सभी चरणों का ठीक प्रकार से पालन किया गया है तो इस चरण में प्रोग्राम लिखना लगभग स्वचालित के बाद कम्पाइलर द्वारा उसका कम्पाइलेशन कराया जाता है। इससे यदि प्रोग्राम में कोई व्याकरण की गलती रह जाती होता है। इसके लिए केवल उस प्रोग्रामिंग भाषा के व्याकरण (Syntax) का ज्ञान होना आवश्यक है। प्रोग्राम लिख लेने है, तो उसका पता चल जाता है और उसे ठीक करके फिर से कम्पाइलेशन कराया जाता है। यह प्रक्रिया तब तक दोहरायी जाती है जब तक कि प्रोग्राम व्याकरण की गलतियों से पूरी तरह मुक्त नहीं हो जाता।
इस चरण में प्रोग्राम का परीक्षण किया जाता है। इसके लिए सबसे पहले एक परीक्षण डाटा (Test Data) तैयार किया जाता है। यह इनपुट डाटा ऐसा होना चाहिए, जिसका आउटपुट हमें पहले से ज्ञात हो, ताकि यह देखा जा सके चलिए जब तक आपको कि प्रोग्राम ठीक वही आउटपुट देता है या नहीं। यदि दोनों में समानता है, तो प्रोग्राम सफल कहा जायेगा। टैस्ट डाटा नहीं लिख सकते। इन तैयार कर लेने के बाद उस डाटा के लिए प्रोग्राम को चलाकर देखा जाता है और कोई गलती पाये जाने पर प्रोग्राम में उपलब्ध है या नहीं आवश्यक सुधार किये जाते हैं। जब परीक्षण का आउटपुट पूरी तरह सन्तोषजनक होता है, तो प्रोग्राम को वास्तविक य श्रम में पड़ जाते हैं। डाटा के साथ प्रयोग करने के लिए दे दिया जाता है।
आप पढ़ चुके हैं कि कोई एल्गोरिथ्म किसी कार्य को करने के लिए एक विशेष क्रम में लिखे गये आदेशों का समूह होता है। ये आदेश इस प्रकार लिखे जाते हैं कि यदि कोई व्यक्ति उनको समझकर उसी क्रम में उनका ठीक-ठीक पालन करता जाये, तो वह कार्य पूरा हो जाता है।
फ्लोचार्ट एल्गोरिथ्म लिखने की एक विधि है, जिसमें एल्गोरिथ्म के आदेशों या कथनों को विशेष प्रकार की आकृतियों के रूप में दिखाया जाता है। अलग-अलग प्रकार के कथनों के लिए अलग-अलग प्रकार की आकृतियों का उपयोग किया जाता है और उन आकृतियों के भीतर उस कथन को संक्षेप में लिखा जाता है। इन आकृत्तियों को उनके पालन के क्रम की दिशा में तीर के चिह्नों द्वारा जोड़ दिया जाता है।
ऊपर के सभी उदाहरणों में हमने जो एल्गोरिथ्म या फ्लोचार्ट बनाये हैं, वे सभी इस तरह के हैं कि प्रथम कधर (या आकृति) में प्रारम्भ करके सभी कथनों का उसी क्रम में पालन करते हुए अंतिम कथन तक पहुंचा जाता है।
सामान्यतया ऐसी स्थिति कम होती है। कई बार हमें कुछ कथनों को छोड़कर अन्य कथनों का पालन करना पड़ता है अर्थात् प्रोग्राम या एल्गोरिथ्म का नियंत्रण अथवा फ्लोचार्ट का प्रवाह अपनी सामान्य दिशा को छोड़कर किमी अन्य दिशा में चला जाता है। इस प्रकार प्रोग्राम के प्रवाह की दिशा बदलने की क्रिया को ब्राँचिंग (Branchting) जाता है।
फ्लोचार्ट में सशर्त ब्राँचिंग को एक डायमंड की आकृति द्वारा दिखाते हैं। डायमंड के अन्दर उस शर्त को लिखा जाता है, जिसकी जाँच की जानी है, और तीरों द्वारा उस शर्त के सत्य सा असत्य होने की स्थिति में पालन किये जाने वाले कथनों या आकृतियों की ओर संकेत किया जाता है।
इस तरह की ब्राँचिंग को बिना शर्त ब्राँचिंग (Unconditional Branching) कहा जाता है।
फ्लोचाटों में बिना शर्त ब्राँचिंग को तीरों द्वारा दिखाया जाता है।
किसी प्रोग्राम या एल्गोरिथ्म में किसी कार्य अथवा कथनों के समूह को बार-बार दोहराने की क्रिया को लूपिंग कहा जाता है।फ्लोचार्ट में लूप के लिए कोई विशेष चिह्न नहीं होता।
किसी बड़े कार्य के लिए कम्प्यूटर प्रोग्राम लिखना एक जटिल एवं कठिन कार्य होता है। यदि कोई कार्य बहुत जटिल है, तो उसको सफलतापूर्वक करने के लिए हम उसको कई छोटे-छोटे कार्यों में बाँट लेते हैं और फिर क्रमा प्रत्येक छोटे कार्य पर ध्यान केन्द्रित करके उसे पूरा कर लेते हैं। इस तरह खण्ड-खण्ड करके कार्य करने से को जटिल से जटिल कार्य भी पूरा किया जा सकता है। लम्बे और जटिल कार्यों के लिए प्रोग्राम लिखते समय भी हम इसी प्रक्रिया का पालन करते हैं और लम्बे प्रोग्राम को कई छोटे भागों में बाँटकर उनके लिए स्वतंत्र रूप से छोटे-छोटे प्रोग्रा लिख लेते हैं। फिर उन सभी छोटे प्रोग्रामों को एक मुख्य प्रोग्राम में जोड़कर एक जगह एकत्र कर लिया जाता है, जिस सम्पूर्ण प्रोग्राम तैयार हो जाता है। इस विधि को मॉड्यूलर प्रोग्रामिंग अथवा संरचनात्मक प्रोग्रामिंग ( Programming) कहा जाता है।
मॉड्यूलर या संरचनात्मक प्रोग्रामिंग के तीन प्रमुख उद्देश्य होते हैं
1. त्रुटि रहित प्रोग्राम तैयार करना,
2. कम से कम समय में प्रोग्राम तैयार करना,
3. प्रोग्राम का रखरखाव तथा उसमें सुधार करके सरल बनाना।
क्रमिक प्रक्रिया (Sequential Process)
निर्णय प्रक्रिया (Decision Process)
दोहराव प्रक्रिया (Repetition Process)
Read Full Blog...
Machine Code (मशीन कोड) कंप्यूटर की असली भाषा है। यह वह भाषा है जिसे आपका कंप्यूटर का प्रोसेसर (CPU) सीधे समझता और execute (निष्पादित) करता है। इसे बाइनरी कोड भी कहते हैं।
कल्पना कीजिए कंप्यूटर एक बहुत ही समझदार जानवर है, लेकिन वह सिर्फ "हाँ" (1) और "नहीं" (0) की भाषा समझता है। मशीन कोड उसी "हाँ" और "नहीं" यानी 0 और 1 की लंबी-लंबी स्ट्रिंग्स (strings) होती हैं।
उदाहरण: 10110000 01100101
यह एक simple instruction हो सकता है जो CPU को बताता है, "संख्या 101 (दशमलव में 5) को एक specific स्थान (register) में रख दो।"
बाइनरी फॉर्मेट: यह सिर्फ 0 (OFF) और 1 (ON) के combination से बना होता है। ये 0 और 1 बिजली के सिग्नल्स को represent करते हैं (0 = no current, 1 = current)।
सीधी Execution: CPU इस कोड को सीधे पढ़ और run कर सकता है। इसे किसी और translation की जरूरत नहीं होती। यह सबसे तेज तरीका है कंप्यूटर को instruction देने का।
मशीन-विशिष्ट: अलग-अलग तरह के CPUs (जैसे Intel, AMD, ARM) की अपनी अलग मशीन भाषा होती है। एक CPU के लिए लिखा गया मशीन कोड दूसरे प्रकार के CPU पर नहीं चलेगा।
मनुष्यों के लिए असमझेय: इंसानों के लिए 0s और 1s के इन लंबे sequences को पढ़ना, याद रखना और लिखना लगभग नामुमकिन है।
कोई भी इंसान सीधे मशीन कोड नहीं लिखता। यह automatic बनता है:
प्रोग्रामर एक High-Level Language (जैसे Python, Java) या Assembly Language में कोड लिखता है।
एक कम्पाइलर (Compiler) या असेम्बलर (Assembler) इस human-readable code को पूरा का पूरा पढ़कर मशीन कोड में translate कर देता है।
यह मशीन कोड एक .exe (Windows) या .out (Linux) जैसी फाइल में save हो जाता है।
जब आप उस program को चलाते हैं, तो CPU सीधे इसी मशीन कोड फाइल को पढ़ता और execute करता है।
Process Flow: प्रोग्रामर का लिखा कोड (C++/Java) → कम्पाइलर → मशीन कोड (0s और 1s) → CPU → रिजल्ट
मान लीजिए आपने C language में लिखा:
int a = 5 + 3;
कम्पाइलर इसे मशीन कोड में कुछ इस तरह बदल देगा (यह just एक example है, actual code much longer होता है):
10110000 00000101 // value 5 को एक जगह रखो
00000100 00000011 // उसमें 3 जोड़ो
10100010 ........ // result को memory में save करो
CPU इन्हीं बाइनरी instructions को एक-एक करके execute करेगा।
सोर्स कोड (Source Code) वह मूल कोड या आदेशों की सूची होती है जिसे एक प्रोग्रामर (Programmer) किसी प्रोग्रामिंग भाषा (जैसे Python, Java, C++) में लिखता है। इसे मानव-पठनीय (Human-Readable) कोड भी कहते हैं क्योंकि यह इंसानों के समझने लायक होता है।
कल्पना कीजिए आप एक रेसिपी लिख रहे हैं। आप हिंदी/अंग्रेजी में लिखेंगे:
"सबसे पहले 2 कप आटा लें"
"उसमें 1 कप पानी मिलाएं"
"अच्छे से गूंथ लें"
यह रेसिपी ही सोर्स कोड है। यह clear और समझने में आसान है।
सोर्स कोड का उदाहरण (Python में):
# यह एक सोर्स कोड है
naam = input("अपना नाम बताएं: ")
umr = int(input("अपनी उम्र बताएं: "))
if umr >= 18:
print("नमस्ते", naam, "! आप वोट दे सकते हैं।")
else:
print("नमस्ते", naam, "! आप अभी वोट देने के लिए छोटे हैं।")
इस कोड को देखकर आप अंदाजा लगा सकते हैं कि यह प्रोग्राम क्या करेगा।
मानव-पठनीय (Human-Readable): यह English के शब्दों और गणित के symbols से बना होता है, जिसे प्रोग्रामर आसानी से पढ़, समझ और बदल सकता है।
टेक्स्ट फाइल: सोर्स कोड साधारण टेक्स्ट फाइलों (.py, .java, .cpp) में save होता है।
निर्माण खंड (Building Blocks): सोर्स कोड ही वह चीज है जिसे कम्पाइलर (Compiler) या इंटरप्रेटर (Interpreter) पढ़ता है और उसे मशीन कोड (0s और 1s) में बदलता है।
लॉजिक और एल्गोरिदम: इसमें प्रोग्राम का पूरा तर्क (Logic) और कार्य करने का तरीका (Algorithm) लिखा होता है।
सोर्स कोड अपने आप में चलने लायक नहीं होता। उसे चलाने के लिए उसे मशीन कोड में बदलना पड़ता है। यह काम दो तरीकों से होता है:
कम्पाइलेशन (Compilation): एक कम्पाइलर पूरे सोर्स कोड को एक साथ पढ़कर एक एक्जिक्यूटेबल फाइल (.exe, .out) में बदल देता है।
Example: C, C++ का कोड
इंटरप्रिटेशन (Interpretation): एक इंटरप्रेटर सोर्स कोड को एक-एक लाइन पढ़ता है और तुरंत execute करता है।
Example: Python, JavaScript का कोड
Process: प्रोग्रामर → सोर्स कोड लिखता है → कम्पाइलर/इंटरप्रेटर → मशीन कोड → कंप्यूटर चलाता है
सोर्स कोड और मशीन कोड में अंतर
सोर्स कोड (Source Code) वह कोड होता है जिसे एक प्रोग्रामर खुद लिखता है। यह इंसानों के लिए बना होता है इसलिए इसे पढ़ना और समझना आसान होता है। सोर्स कोड English के शब्दों (जैसे if, else, print) और गणित के चिन्हों (जैसे +, -, *) से मिलकर बना होता है। यह एक साधारण टेक्स्ट फाइल की तरह होता है जिसे कोई भी टेक्स्ट एडिटर खोलकर देख और बदल सकता है। सोर्स कोड में प्रोग्राम का पूरा तर्क और काम करने का तरीका लिखा होता है।
मशीन कोड (Machine Code) वह कोड होता है जिसे कंप्यूटर का प्रोसेसर (CPU) सीधे समझता और चला सकता है। यह सिर्फ 0 और 1 की भाषा में होता है, जिसे बाइनरी कोड भी कहते हैं। इंसानों के लिए इसे पढ़ना या समझना लगभग नामुमकिन होता है। मशीन कोड सोर्स कोड से automatic बनता है, जब एक कम्पाइलर या इंटरप्रेटर सोर्स कोड का अनुवाद करता है। यह एक बाइनरी फाइल के रूप में होता है जिसे सीधे execute किया जा सकता है।
Read Full Blog...High-Level Language (HLL) क्या है?
एक High-Level Language (HLL) या उच्च-स्तरीय भाषा एक प्रोग्रामिंग भाषा है जो इंसानों (प्रोग्रामर) के लिए बनाई गई है। यह English के शब्दों और गणित के सिंबल्स (जैसे +, -, *, /) से मिलकर बनी होती है, जिसे आम इंसान आसानी से पढ़ और समझ सकता है।
इसका नाम 'उच्च-स्तरीय' इसलिए है क्योंकि यह कंप्यूटर के हार्डवेयर (जैसे प्रोसेसर, मेमोरी) से बहुत दूर एक 'ऊँचे स्तर' पर काम करती है। प्रोग्रामर को यह जानने की जरूरत नहीं होती कि कंप्यूटर का CPU अंदर से कैसे काम करता है।
उदाहरण के लिए, एक High-Level Language में लिखा गया कोड:
answer = 5 + 3 if answer > 10: print("बड़ी संख्या") else: print("छोटी संख्या")
इस कोड को देखकर आप अंदाजा लगा सकते हैं कि यह क्या कर रहा है, क्योंकि यह English और गणित के सरल नियमों जैसा दिखता है।
इंसानों के लिए आसान (Human-Friendly): इसे लिखना, पढ़ना और समझना आसान है क्योंकि यह हमारी बोलचाल की भाषा के करीब है।
मशीन से स्वतंत्र (Machine Independent): HLL में लिखा गया एक program अलग-अलग तरह के कंप्यूटरों (जैसे Windows, Mac, Linux) पर चलाया जा सकता है। बस उसके लिए अलग-अलग कम्पाइलर की जरूरत होती है।
कोड छोटा और सरल (Short & Simple Code): एक छोटे से code लाइन में बहुत बड़ा काम करवाया जा सकता है। जैसे c = a + b लिखने भर से दो numbers जोड़े जा सकते हैं।
डीबग करना आसान (Easier to Debug): इसमें गलतियाँ (errors) ढूंढना और सुधारना相对 आसान होता है।
Python
Java
C++
JavaScript
C#
PHP
Ruby
एक High-Level Language को कंप्यूटर सीधे नहीं समझ सकता। कंप्यूटर सिर्फ 0 और 1 (बाइनरी कोड) की भाषा समझता है। इसीलिए कम्पाइलर की जरूरत पड़ती है।
कम्पाइलर का काम होता है High-Level Language में लिखे गए कोड को पूरा का पूरा पढ़कर उसे कंप्यूटर की बाइनरी भाषा (मशीनी कोड) में अनुवाद (Translate) करना। तब जाकर कंप्यूटर उस program को चला पाता है।
सरल शब्दों में: प्रोग्रामर → High-Level Language में कोड लिखता है → कम्पाइलर → उसे मशीनी कोड में बदलता है → कंप्यूटर → प्रोग्राम चलता है।
Low-Level Language (LLL) क्या है?
एक Low-Level Language (LLL) या निम्न-स्तरीय भाषा वह भाषा है जो सीधे कंप्यूटर के हार्डवेयर (विशेष रूप से CPU) से संवाद करती है। यह मशीन के बहुत करीब होती है और इंसानों के लिए समझने में कठिन होती है।
उदाहरण के लिए: जबकि High-Level Language में आप लिखते हैं a = 5 + 3, Low-Level Language में यही काम करने के लिए आपको multiple complex instructions लिखनी पड़ सकती हैं।
मशीनी भाषा (Machine Language - 1st Generation)
यह 0s और 1s (बाइनरी कोड) में होती है
CPU इसे सीधे समझता और execute करता है
Example: 10110000 01100101
असेम्बली भाषा (Assembly Language - 2nd Generation)
यह मशीनी भाषा से थोड़ी आसान होती है
इसमें Mnemonics (संक्षिप्त कोड) का use होता है
Example: MOV AL, 61h
मशीन निर्भर (Machine Dependent)
अलग-अलग processors के लिए अलग assembly code
Intel processor के लिए लिखा code ARM processor पर नहीं चलेगा
हार्डवेयर तक सीधी पहुंच
Memory, registers और hardware components को directly access कर सकते हैं
उच्च performance
Direct hardware access के कारण programs तेज चलते हैं
कोई translation overhead नहीं होता
समझने में कठिन
केवल 0s और 1s या cryptic codes
Debugging और maintenance मुश्किल
ऑपरेटिंग सिस्टम बनाने में
डिवाइस ड्राइवर्स लिखने में
एम्बेडेड सिस्टम programming में
रियल-टाइम सिस्टम में
फर्मवेयर विकास में
High-Level Language (उच्च-स्तरीय भाषा):
यह वह भाषा है जो इंसानों के लिए बनाई गई है। इसे पढ़ना, लिखना और समझना आसान होता है क्योंकि यह English के शब्दों और गणित के चिन्हों से मिलकर बनी होती है। जैसे Python, Java, C++ जैसी भाषाएँ। इनमें लिखा कोड मशीन से स्वतंत्र होता है, यानी एक ही कोड को अलग-अलग कंप्यूटरों पर चलाया जा सकता है। इनमें programming करना तो आसान होता है लेकिन ये थोड़ी धीमी होती हैं क्योंकि इन्हें चलाने से पहले कम्पाइलर या इंटरप्रेटर की मदद से मशीनी भाषा में बदलना पड़ता है।
Low-Level Language (निम्न-स्तरीय भाषा):
यह वह भाषा है जो सीधे कंप्यूटर के हार्डवेयर से बात करती है। इसे इंसानों के लिए समझना बहुत मुश्किल होता है क्योंकि यह बाइनरी कोड (0 और 1) या Assembly जैसी संक्षिप्त कोड में होती है। यह मशीन पर निर्भर होती है, यानी अलग-अलग प्रोसेसर के लिए अलग कोड लिखना पड़ता है। इसमें लिखे प्रोग्राम बहुत तेज चलते हैं क्योंकि उन्हें किसी translation की जरूरत नहीं होती, लेकिन इन्हें लिखना और डीबग करना बहुत कठिन होता है। इसका इस्तेमाल ज्यादातर ऑपरेटिंग सिस्टम, डिवाइस ड्राइवर या फर्मवेयर बनाने में होता है।
Read Full Blog...डाटाबेस सूचनाओं का एकत्रीकरण और वांछित डाटा अंश को व्यवस्थित करने की प्रक्रिया के डाटाबेस कहा जाता है। डाटाबेस को आप इलेक्ट्रॉनिक फाइलिंग प्रणाली मान सकते हैं।
डाटाबेस मैनेजमेंट सिस्टेम (DBMS) कम्प्यूटर प्रोग्रामों या सॉफ्टवेयर का एकत्रीकरण है, जो संचयन परिवर्तन और डाटाबेस से सूचना प्राप्त करने की अनुमति देता है। अनेक प्रकार के
DBMS उपलब्ध हैं. उनका विस्तार छोटी प्रणालियाँ जो पर्सनल कम्प्यूटर पर काम करते हैं, से लेकर बडी प्रणालियों जो मेइनफ्रेग्स पर काम करते हैं, तक है। एक्सेस (ACCESS), फॉक्सप्रो (FoxPro), और डीबेस (dBase) इसके उदाहरण हैं।
रिलेशनल डाटाबेस, डाटा मदों का एकत्रीकरण और उनका औपचारिक निर्धारित टेबलों के सेट के रूप में संगठित करना है, जिसमें से डाटा को प्राप्त किया जा सकता है या डाटाबेस टेबलों को पुनःसंगठित किये बिना उनका पुनःएकत्री करण किया जा सकता है।
रिलेशनल डाटाबेस सभी डाटाओं को टेबल्स में संचित करता है। डाटा टेबल पंक्तियों औरस्तम्भों का समूह है। यह अत्यन्त महत्वपूर्ण है, क्योंकि इसके घटकों को छाँटने का पूर्व निर्धारित क्रम नहीं है। प्रत्येक पंक्ति, स्तम्भों का समूह है जिसमें केवल एक मूल्य होता है। एक ही टेबल के सभी पंक्तियों में एक ही समूह के स्तम्भ होते है।
रिलेशनल डाटाबेस सिस्टेम (RDBMS), डाटाबेस मैनेजमेंट सिस्टेम (DBMS), का एक प्रकार है जो डाटा को संबंधित टेबलों के रूप में संचित करता है। रिलेशनल डाटाबेस सशक्त हैं क्योंकि उनसे डाटा किस प्रकार संबंधित है
Read Full Blog...भाषा एक संचार साधन है। साधन है। 'कम्प्यूटर के साथ संचार करने के लिए प्रत्येक भाषा चिहनों, वर्षों, शब्दों (मुख्य शब्द) और नियमों (वाक्य संरचना) से निहित होती है। कम्प्यूटर भाषाओं का उपयोग, सभी अनुप्रयोग सॉफ्टवेयर पैकेज, संकलक, प्रचालन प्रणालियों को बनाने में किया जाता है। हम. कम्प्यूटर भाषाओं को तीन स्तरों में वर्गीकृत कर सकते हैं: वे निम्न प्रकार है:
1. मशीनी भाषा
2. निम्नस्तरीय भाषा या असेम्ब्ली भाषा
3. उच्च स्तरीय भाषा
कम्प्यूटर कंवल दो अंकों का उपयोग कर लिखे गये प्रोग्राम का निष्पादन कर सकता है। इस प्रकार के प्रोग्राम को मशीनी भाषा प्रोग्राम कहा जाता है। क्योंकि इन प्रोग्रामों में मात्र '0' और 1' का ही प्रोग्राम किया जाता है अतः जटिल समस्याओं के हल के लिए प्रोग्राम बनाना कवित है। इसके अतिरिक्त एक व्यक्ति द्वारा लिखा गया मशीनी भाषा प्रोग्राम दूसरे व्यक्ति के लिए समझने में कठिन होती है। वस्तुत, कम्प्यूटर के उपयोगकर्ता मशीन का उपयोग कर प्रोग्राम नहीं लिखते। एक मशीन के लिए लिखे गये प्रोग्राम का दूसरे प्रकार के कम्प्यूटर पर प्रयोग नहीं किया जा सकता अर्थात् प्रोग्राम मशीन आधारित होते हैं।
उच्च स्तरीय भाषाएँ मानवी भाषाओं के करीब होती है, तथा निम्न स्तरीय भाषाएँ हार्डवेयर करीब होती है।
असेम्ब्ली भाषा में, समस्या का हल करने के लिए प्रोग्राम तैयार करने में निमोनिय (Mnemonic) कोडों का उपयोग किया जाता है। नीचे दर्शाया गया प्रोग्राम असेम्ब्ली भाष प्रोग्राम है
A पढ़ें। A का मूल्य पढ़ेगा
B जोडे। A के साथ B का मूल्य जोडेग
हाल्ट HALT। निष्पादन रोकेगा
FORTRAN (Formula Translation), BASIC (Beginner's All Symbolic Instruction Code), COBOL (Common Business OrienteLanguage), हाल ही में विकसित प्रोग्रामिंग भाषाएँ जैसे विजुअल फॉक्स प्रो. विजुअल बेशिक जोड़ने के लिए निम्नलिखित बेसिक भाषा प्रोग्राम लिखा गया है। (VB), विजुअल C++ (VC++) आदि सॉफ्टवेयर डेवलपरों में लोकप्रिय है।
अनुवाद प्रोग्राम (Translation Programs) कहलाते हैं। इन अनुवाद प्रोग्रामों का उपयोग कर, कम्प्यूटर द्वारा पढ़े जाने योग्य प्रोग्रामों को अन्तरित किया जाता है। संकलक और दुभाषियों का उपयोग उपयोगकर्ता प्रोग्राम को मशीनी भाषा में अनुवाद करने के लिए किया जाता है।
कम्पाइलर उच्च स्तरीय भाषा में लिखे प्रोग्राम को निष्पादन योग्य मशीनी अनुदेशों में अनुदित करता है। स्त्रोत प्रोग्राम की प्रत्येक पंक्ति को इनपुट माना जाता है और फिर उसे सुलभबनाया जाता है। फिर इसे एक या अनेक पंक्तियों वाले मशीनी भाषा उद्देश्य कोडों में परिवर्तित किया जाता है। संकलन के दौरान होने वाली त्रुटियों से आपको अवगत कराया जाता है। यदि संपूर्ण प्रोग्राम त्रुटिहीन हो, तो, संकलन कर उद्देश्य कोड तैयार किया जाता है। भविष्य में उपयोग के लिए इस उद्देश्य कोड़ का मण्डारण किया जाता है।
COBOL एवं C भाषाओं के कम्पाइलर, इसके उदाहरण हैं।
यह भी एक अनुवाद प्रोग्राम है जिसका उपयोग करके उच्चस्तरीय भाषा प्रोग्राम को मशीनी भाषा प्रोग्राम में अनुवाद किया जाता है। किन्तु यह अनुदेशों को पंक्ति-दर-पंक्ति में अनुवाद और निष्पादन करता है।
BASIC भाषा दुभाषित भाषा का श्रेष्ठ उदाहरण है।
यह एक प्रकार का अनुवाद प्रोग्राम है जिसका उपयोग असेम्ब्ली भाषा प्रोग्राम को मशीन भाष प्रोग्राम में अनुवाद करने के लिए किया जाता है।
चतुर्थ पीढ़ी भाषा एक उच्च स्तरीय भाषा है जिसका उपयोग विशेषकर, सशक्त अर्थ और वाक्य रचनावाले अनुप्रयोग प्रोग्रामिंग के लिए किया जाता है। प्रोग्रामरों को अत्यधिक गति से प्रणाली को विकसित करने की सुविधा उपलब्ध कराता है।
4GL. इस तरह प्रक्रियाकृत और प्रतिकृत है कि उपयोगकर्ता, कम्प्यूटर में प्रक्रियाकरण का कार्य कैसे पूरा होता है. इसकी जानकारी के बिना ही अपनी आवश्यकताओं का उल्लेख कर सकें।
यद्यपि प्यूर 4GL में एक कमी यह है कि यह मात्र विकास के छोटे और अति उच्च विशिष्ट क्षेत्र की समस्या का ही हल कर सकता है। स्क्रीन पेइंटर, रिपोर्ट जेनरेटर और उपयोगकर्ता क्वेरी लैंगुएज आदि प्यूर चतुर्थ पीढ़ी भाषाएँ हैं, प्रणाली विकास प्रक्रिया में इनमें से प्रत्येक का सीमित उपयोग होता है।
चतुर्थ पीढ़ी भाषाओं के इस एकीकरण को FOURTH GENERATION ENVIRONMEN (4GE) के नाम से जाना जाता है। प्यूर" चतुर्थ पीढ़ी भाषाओं के संघटक:
एन्ड-यूसर क्वेरी लैंगुएज (उदा. SQL),
स्क्रीन फॉरमाटर (उदा. SQL* फॉर्म में ओरैकल स्क्रीन पेइंटर),
रिपोर्ट जेनरेटर
ओरैकल चतुर्थ पीढ़ी भाषा है।
डाटा डिक्शनरी उपयोगकर्ता डाटाबेस न होकर सिस्टम डाटाबेस है, जिसमें डाटा के विपरी मेटाडाटा निहित होता है।
डाटाबेस मैनेजमेंट सिस्टेम दो प्रकार से कार्य करता है:
यह 4GE के संघटकों का उपयोग कर विकसित प्रणालियों के फाइलों का रखरखाव करता है।
यह वह सॉफ्टवेयर है जो डाटा डिक्शनरी का प्रबंधन करता है।
Read Full Blog...

I want to Hire a Professional..